GPT-2 Clone From Sratch
A reimplementation of OpenAI's GPT-2 in PyTorch.
Image Gallery
Click on an image to read more about it.
GPT-2 in Action
This is my implementation of GPT-2 (loaded with the official weights from HuggingFace) running inference on the prefix: "Hello, I'm a language model,". It produces intelligible output, though not fully coherent, as it is a relatively small model.

Calculating Self-Attention via Matrix Multiplication
This is some rough work I did to understand how matrix operations can implemented functionality that would otherwise be realized through loops. By using matrix multiplication and GPUs (or SIMD processors) we can significantly speed up execution. I then used this when implementing masked self-attention in the transformer heads.
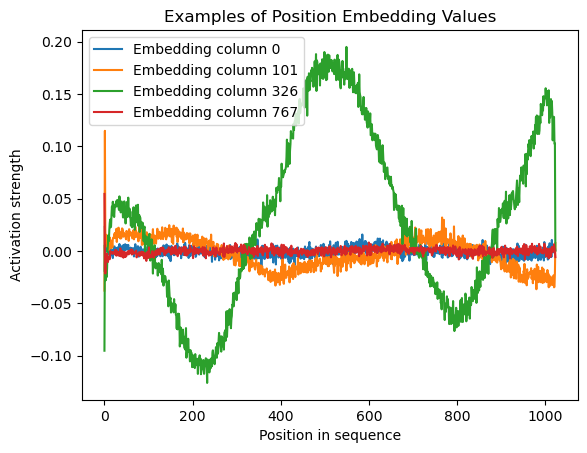
Position Embedding Values for Random Columns
This graph shows the position embedding values (from 0 to 1024, which is the sequence length) for four randomly-chosen columns in the GPT-2 embedding matrix. Interesting patterns are observed, though they are difficult to make sense of.
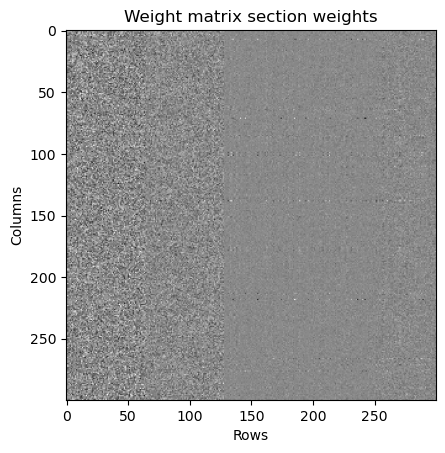
Visualization of a Random Weight Matrix
This staticky-looking image is a visualization of one of the weight matrices in GPT-2. Specifically, it is first 300 rows and columns of the first self-attention head. Lighter shades mean higher values. Notice how there are some patterns that can be observed (some areas are more smooth/less coarse). Similar to the positional embeddings graph in the previous image, it is difficult to decipher this information.
Project Overview
PyTorch GPT-2 clone based on Andrej Karpathy's material. Implements manual scaled dot-product attention and PyTorch flash attention (scaled_dot_product_attention) with causal masking. Uses GELU, LayerNorm pre-norm, residual connections, and tied input/output embeddings.
Attention
Two backends: manual attention with explicit QK^T/√d and softmax, and flash attention via PyTorch for speed and memory efficiency. Autoregressive mask is a lower-triangular buffer of shape (1,1,T,T).
Initialization and Optimizer
Weights follow GPT-2 init (Normal(0, 0.02); position embeddings 0.01). Residual branches scale down by 1/√(2·n_layer) via a flag on residual-adjacent projections. AdamW uses decoupled weight decay on weight matrices only; biases and LayerNorm weights are excluded.
Pretraining and Data
Supports token/position embeddings for a vocab of 50,257 and context length 1024. Trains on FineWeb-Edu 10B. Uses gradient checkpointing and optional DDP for multi-GPU. Checkpoints store optimizer and model state for pausing and resuming training.
HF Compatibility
Includes a loader to map Hugging Face GPT-2 weights into this model, transposing QKV and MLP projection matrices as needed and skipping masked bias buffers.
Sampling & Eval
Greedy or temperature sampling over logits (B,T,V). Perplexity evaluation via average negative log-likelihood. Flash attention can be toggled per block for ablations.
Tokenizer Reimplementation
To better understand GPT-2's preprocessing pipeline, I reimplemented the byte pair encoding (BPE) tokenizer from scratch in a separate repository: llm-tokenizer. It reproduces GPT-2's 50,257-token vocabulary, byte-level encoding, and BPE merges. The tokenizer works independently of Hugging Face and outputs exact token IDs for any input text.